
2026年5月28日、AnthropicがClaude Codeに「Dynamic Workflows(ダイナミック・ワークフロー)」という新機能を発表しました。1回の実行で最大1,000体ものサブエージェントを動かせる、という触れ込みです。
翌日の5月29日。39歳・プログラミング初心者の私は、さっそくこの機能を自分の作業で試してみました。
「最大1,000体」という規模感を見て、まず思ったのは「これなら今やっているリサーチ作業も、かなりスピードアップできそうだ」ということ。期待に背中を押されて、発表の翌日にはもう自分の作業で試していました。
結論から言うと、「最大1,000体」という触れ込みの派手さと、実際に複数のエージェント構成で試した感触には、いい意味でも悪い意味でもギャップがありました。この記事では、初心者が等身大で体験した次の3つをお伝えします。
- Dynamic Workflowsを起動すると、画面で何が起きるのか
- 「期待」と「実態」のあいだにあった4つの発見
- 処理時間・コストの実測データ(従来のやり方との比較)
第1章:そもそもDynamic Workflowsって何?
Dynamic Workflows(以下、DW)を一言でいうと、「1つの大きな作業を細かく分けて、別々のAI作業員に同時にやらせる仕組み」です。
この「AI作業員」のことを、Claude Codeではサブエージェントと呼びます。1人の作業員が全部の仕事を順番にこなすのではなく、複数の作業員に手分けして同時進行させるイメージですね。
ここで初心者がつまずきやすい言葉を先に整理しておきます。
- 並列=同時に進める
- 直列=順番に1つずつ進める
DWは、この「並列」を大きく広げられるのが目玉です。ここで数字を正確に押さえておくと、同時に動かせるのは最大16体まで。1回の実行で使える合計が最大1,000体です(「1,000体が一斉に並列で走る」わけではない点に注意)。
そして、同時に進められるのは「互いに関係のない(依存していない)作業」だけ。「Aが終わらないとBができない」という関係の作業は、どうしても順番待ちが発生します。この点が、後で出てくる第4章の発見につながります。
Anthropicの公式ブログでは、DWの実例として、Bunというソフトウェアの75万行のコードベースを、ZigからRustという別のプログラミング言語に11日で移植し、テスト通過率99.8%を達成したと紹介されています(出典:Anthropic公式ブログ)。人間が手作業でやれば数ヶ月かかる規模です。
ただし、ここで大事な注意点を2つ。
- DWは2026年5月28日時点で「研究プレビュー」段階です。まだ実験的な機能で、仕様が変わる可能性があります。
- DWはサブエージェントを多く動かすぶん、普通のセッションよりトークン(利用枠)を多く消費します。いきなり大きなタスクで回さず、まず小さなタスクで試して感覚をつかむのがおすすめです。
第2章:なぜ試そうと思ったか
私がDWを試したかった一番の理由は、note記事のネタ収集をもっと効率化したかったからです。
私は今、ブログ運営を始めていて、noteも近いうちに始める予定です。その記事ネタを集めるのに、いくつかの手順を組み合わせたリサーチ用の作業を用意して使っています。このリサーチが結構時間のかかる作業で、もっと速くできないかとずっと考えていました。そこにDWの発表が来た、というわけです。
もう1つは、単純に新機能が面白そうだったこと。リリース直後のものを自分でいじってみたい、という好奇心が後押ししてくれました。
第3章:起動するとこうなる
では、実際にどう操作したのか。拍子抜けするくらいシンプルでした。
やったことは、Claude Codeに「note記事のリサーチをDynamic Workflowで動かして」と日本語で頼んだだけです。特別なコマンドも、難しい設定もいりません。
すると、ターミナル(黒い画面でコマンドを打つツール)に、こんな確認画面が出ました。
Run a dynamic workflow?
note記事ネタ収集の作業
6体構成のDW動作確認テスト(researcher→summarizer→fact-checker→
pattern-analyst→analyst→memo-writer)
This dynamic workflow will spin up multiple subagents across the following phases:
1. ①収集 researcher — 定点観測+カテゴリ収集(合計20本上限厳守)
2. ②要約 summarizer — 全記事を3行要約+キーポイント
3. ③裏取り fact-checker — 収益化数字・強い主張・規約系を一次情報で検証
4. ④型抽出 pattern-analyst — 4観点でパターン抽出
5. ⑤差別化 analyst — 競合マップ・差別化候補3-5案
6. ⑥統合保存 memo-writer — 5セクション構造に統合・保存
Dynamic workflows can use a lot of tokens quickly by running many subagents
in parallel — which counts against your usage limit.
Stop a running workflow at any time with /workflows,
or disable dynamic workflows in /config.
1. Yes, run it
2. View raw script
3. Noポイントは、いきなり動き出すのではなく「実行していい?」と確認してくれること。トークン(AIの処理量。多いほどコストもかかる)を大量に使う可能性があることも、ちゃんと警告してくれます。停止は /workflows、無効化は /config から、という案内まで親切でした。

そして「1. Yes, run it」を選ぶと、JavaScriptのプログラムが自動生成されました。プログラミング初心者の私が自分では絶対に書けないコードが、頼んだだけで出てきたのです。生成されたコードは、こんな骨格でした(要点を抜粋)。
export const meta = {
name: 'note-research-dw-test',
description: 'note記事ネタ収集 6体構成のDW動作確認テスト',
phases: [
{ title: '①収集 researcher', detail: '定点観測+カテゴリ収集(合計20本上限厳守)' },
{ title: '②要約 summarizer', detail: '全記事を3行要約+キーポイント' },
{ title: '③裏取り fact-checker', detail: '収益化数字・強い主張・規約系を一次情報で検証' },
{ title: '④型抽出 pattern-analyst', detail: '4観点でパターン抽出', model: 'opus' },
{ title: '⑤差別化 analyst', detail: '競合マップ・差別化候補3-5案', model: 'opus' },
{ title: '⑥統合保存 memo-writer', detail: '5セクション構造に統合・保存', model: 'opus' },
],
}
// ① researcher:記事を収集
const research = await agent(`...収集の指示...`, { agentType: 'researcher' })
// ② summarizer:researcherの結果を受け取って要約
const summary = await agent(`...要約の指示...
${research}`, { agentType: 'summarizer' })
// ③ fact-checker:summarizerの結果を裏取り
const factcheck = await agent(`...裏取りの指示...
${summary}`, { agentType: 'fact-checker' })
// (④型抽出 → ⑤差別化 → ⑥統合保存 と続く)※実際の収集フェーズは複数の担当が並列で動きますが、ここでは流れが分かるように簡略化しています。
注目してほしいのが、各行の頭にある await という単語。これは「前の処理が終わるまで待ってね」という指示です。つまり「researcherが収集を終える→その結果をsummarizerが受け取って要約する→さらにfact-checkerが裏取りする」という具合に、バトンを渡しながら順番に処理する設計になっていました。この await が、第4章の発見の伏線になります。
正直に言うと、起動そのものはあっけないほど簡単でした。「Run a dynamic workflow?」の確認画面で「Yes」を選ぶだけ。特別な操作は必要ありませんでした。
第4章:期待と実態のギャップ・4つの発見
ここがこの記事の山場です。「全部が並列で動いて時短になる」という期待を持って臨んだ私が、実際に動かして気づいた4つのことをお伝えします。
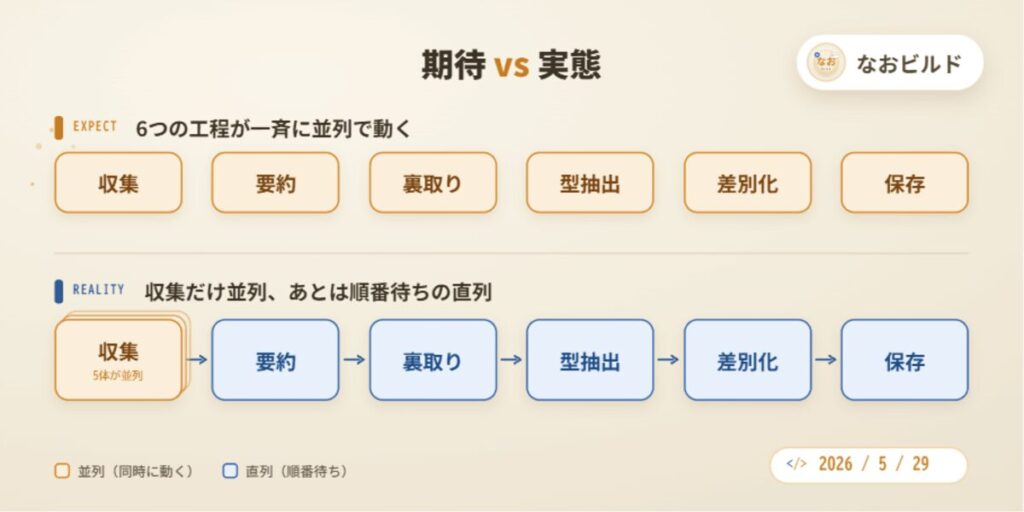
▲ 期待は「全部が一斉に並列で動いて時短」。でも実態は「収集だけが並列で動き、その後は前の結果を待つ一本道(直列)」になりました。
発見①:Claude Codeは「依存関係」を理解して、並列と直列を使い分ける
第3章で触れた await の正体がこれです。私のワークフローでは、最初の「収集」だけは複数の作業を同時に進められました。実際、情報収集の複数の担当が一斉に動き出したのです。ところが、その後の「要約→裏取り→…」は、前の担当の結果がないと次に進めません。つまり依存関係があるぶんは並列にできないのです。
- 期待:すべてが一斉に動いて、まるごと時間が短縮される
- 実態:独立している「収集」は並列で動いたが、依存関係のある「要約以降」は順番待ちの直列になった
Claude Codeは、私が組んだタスクの依存関係を読み取って、「ここは同時にやれる」「ここは順番にやるしかない」と判断し、awaitで組み合わせてくれていました。並列と直列を、タスクの性質に応じて自動で使い分けていたのです。
収集の複数体が一斉に動き出したのには「お、ちゃんと並列で動いてる!」と感心しました。でもその後は1個ずつ順番待ち。「並列って聞いてたから全部同時かと思ったのに、そういうわけじゃないのか」と、ちょっと意外でした。
発見②:DWは万能じゃない
発見①の続きです。これで「DWの本領発揮はどんなときか」がハッキリ分かりました。
- 向いている:各作業が互いに独立しているタスク(複数トピックの同時リサーチなど)
- 向いていない:A→B→Cと依存が深いタスク(今回の私の構成がまさにこれ)
依存が深いタスクでは、DWを使っても普通の直列処理と大きくは変わりません。「並列のパワー」を受けられるのは、独立した作業がたくさんあるワークフローだけ、というのが体験で腹落ちしました。
正直「何でも速くなるわけじゃないのか」と少しガッカリしました。でも、まだ私の作業の組み方がDWを活かしきれていないだけ、とも気づけたんです。
発見③:プロンプトの指示が忠実に反映される
これは嬉しい驚きでした。私が指示文に「上限20記事を厳守」と書いたら、自動生成されたスクリプトの中に、わざわざ ★★上限20記事を厳守 と強調付きで書き込まれていたのです。
「比較用に保存先を別ファイルにして」という指示も、ちゃんと該当エージェントへの指示に反映されていました。こちらが書いた指示の品質が、そのままコードに出る。プロンプト(AIへの指示文)を丁寧に書くことの大切さを、実物で見せられた気分です。
自分が「厳守」と書いた一言を、強調付きでそのままコードに反映してくれていて、「ちゃんと聞いてくれている」と素直に嬉しくなりました。
発見④:すごいのは「コードが書ける」ことじゃなく、「AIたちを束ねる仕組み」まで自動で作れること
正直に言うと、「日本語で頼んだらコードが出てくる」こと自体は、普段のClaudeでも体験済みで、そこまでの驚きはありませんでした。DWが本当にすごいのは別のところ。複数のAIを「どう分担させて、どう同時に動かすか」という”監督の仕事”まで、自動でスクリプトにしてくれるんです。しかもその段取りはスクリプト側が持つので、Claude本体の”作業メモ”を圧迫しない。だから大量のAIを動かしても、最後の答えだけがスッキリ返ってくる。Claude Codeが「1回で答えるツール」から「AIたちの現場監督」に進化したんだな、と感じました。
ただ、今回の私の構成は依存が多くて直列中心だったので、この”現場監督”の本領をフルに見るのは次回のお楽しみ、というところです。
第5章:実測データ(DWあり vs なし)
体感だけでは語れないので、同じリサーチ作業を「DWなし(従来のやり方)」と「DWあり」で実行して比べてみました。結果がこちらです。
| 比較項目 | DWなし(従来) | DWあり(今回) |
|---|---|---|
| 処理時間 | 21分43秒 | 11分18秒(約半分) |
| API換算コスト | 約$2.36 | 約$1.67(むしろ微減) |
| 5時間セッション消費 | 6% | 6%(同等) |
| 可視性 | なし | /workflowsで進捗が見える |
| 制御性 | Ctrl+Cで停止 | 安全に停止・一時停止できる |
数字で見ると、一番のインパクトは処理時間が約半分になったこと。21分43秒が11分18秒です。リサーチ時間が半分になるのは、シンプルにありがたい。
そして意外だったのがコスト。「並列でたくさん動かすぶん高くなるだろう」と思っていたのに、DWありのほうが約$1.67と、むしろ少し安くなりました。エージェント間のバトンの受け渡しが効率化されたのが効いたようです(ここは正直、想定外でした)。
もう1つ、予想外に良かったのが可視性。/workflows という画面で、今どのエージェントがどこまで進んでいるかがリアルタイムで見えるのです。「AIが今、何をやっているのか分かる」という安心感は、使ってみて初めて価値が分かりました。
ただ、正直な疑問も残っています。「この差が本当にDWだけの効果なのか、それとも別の要因も混じっているのか」——1回の比較だけで断言はできないな、というのが等身大の感想です。
一番驚いたのは処理時間。約半分になって「DWを入れるだけでこんなに違うのか」と実感しました。コストは、大量に動かすぶん高くなると考えていたのに、ほとんど変わらず(むしろ微減)。今回はまだエージェントが少ないからかもしれませんが、そこも良い意味で意外でした。
第6章:でも「失敗ネタ」じゃない3つの理由
「並列で動くと思ってたら、収集以外は一本道だった」と聞くと、失敗談に聞こえるかもしれません。でも、私はこれを失敗だとは思っていません。期待通りではなかったけれど、得たものは大きかったからです。理由は3つ。
- 速度効果を数値で確認できた。処理時間が約半分という結果は、体感ではなくデータとして残りました。再現できれば、他の作業にも応用できます。
- 可視性・制御性のメリットを確認できた。
/workflowsで進捗が見え、途中で安全に止められる。この2つは「このリサーチ作業に本格的に取り入れるかどうか」を判断する材料になりました。 - 次回への学びが得られた。「DWは独立した並列タスクで真価を発揮する」と分かったので、次はそういうタスクで試せばいい。試し方の解像度が上がりました。
うまくいかなかった部分も含めて「学習資産」になる。これは新しいことに試行錯誤している人みんなに共通する感覚じゃないかなと思います。
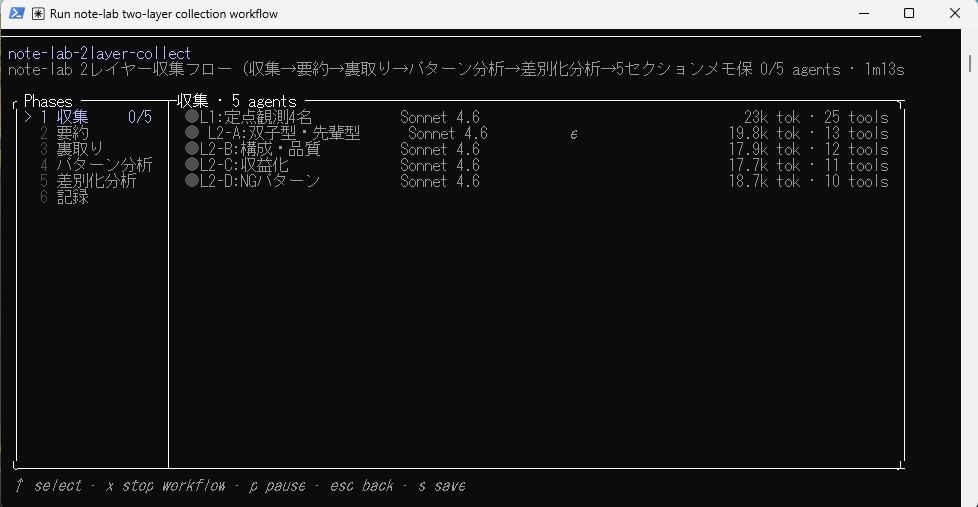
これが失敗じゃないと思えたのは、実行中に/workflowsの画面を見たとき。DWなしではClaude Codeが何をしているか見えなかったのに、各エージェントの進み具合もエラー箇所も一目で分かる。「今までと全然違う」と感じました。コスト面は様子を見つつですが、この可視性と時短だけでも、普段のリサーチ作業に取り入れたいと思える体験でした。
第7章:Dynamic Workflowsを使うべき/使うべきでない場面
初心者なりに1回試した結論として、向き不向きを整理しておきます。
使うべき場面
- 各タスクが互いに独立している作業(複数トピックの同時リサーチ、複数ファイルの同時解析など)
- 大規模なコードの移植・リファクタリング(公式が挙げたBunの事例がまさにこれ)
- 進捗の可視化や、途中で止める制御がほしい作業
使うべきでない場面
- 小規模なタスク(普通の直列処理で十分。わざわざDWにする意味が薄い)
- A→B→Cと依存が深いワークフロー(並列の恩恵をほぼ受けられない)
- 研究プレビュー段階のリスク(仕様変更・課金変更)を許容できない本番環境
向いていると感じたのは収集系。ブログやニュース系のリサーチはどれも並行できるので、DWで時短できそうです。逆に、集めた情報を1本にまとめて書く作業は依存が深く不向き。ただ、1つの記事を複数の書き手に同時に書かせて読み比べる形なら、執筆でも並列を活かせるかもしれません。
締め:次は何を並列化する?
今回の実験を一言でまとめると、「実験的に試す価値は十分ある。ただし本番採用は向き不向きで判断」でした。「全部が並列で動いて時短になる」と期待して始めましたが、得られたのは「自分のタスクの形に合わせてAIが賢く設計してくれる」という、もっと地に足のついた発見でした。
最後に、これから試す人へ大事な注意を2つ。DWは2026年5月28日時点で研究プレビュー段階で、仕様が変わる可能性があります。そしてDWはトークンを大量に消費します。いきなり大きなタスクで回さず、小さく試すところから始めるのがおすすめです。
次は、今回活かせなかった「並列のパワー」を、もっと独立性の高いタスクで試してみたいと思っています。
今回、並列にできたのは収集だけ。次はもっと独立した作業をたくさん並列で回せる形にしてみたいです。DWを使いこなせるよう、自分の作業の仕組みをコツコツ改善していきます。
あなたなら、どんな作業を並列化したいですか? よかったらコメントで教えてください。
前回の記事もどうぞ:39歳プログラミング初心者がBMI計算機を作った話


コメント